行业背景
自然语言处理(Natural Language Processing,简称NLP)是一门交叉学科,它结合了计算机科学、人工智能和语言学的知识,旨在使计算机能够理解、解释和生成人类语言。NLP的核心是构建能够理解和交流自然语言的算法,从而缩小人与机器之间的交流鸿,沟自然语言处理可以分为两大类:自然语言理解(NLU)和自然语言生成(NLG)。自然语言理解关注于机器对人类语言的理解和解释,包括语法分析、情感分析、实体识别等。而自然语言生成则是关注于机器如何以自然、流畅的语言输出信息,包括自动文摘、机器翻译和对话系统等
自然语言处理(NLP)的发展历史可以追溯到20世纪50年代,从最初的基于规则、统计方法,到现代的深度学习、机器学习技术, 自然语言处理的早期尝试开始于1950年代。研究者开始使用规则基础的方法来解决自然语言处理问题,例如通过编写语法规则来进行句法分析。1970年代至1990年代,随着统计学的引入,自然语言处理开始转向基于数据的方法,研究者开始使用统计模型来处理语言问题 ,进入21世纪,随着机器学习的崛起,自然语言处理开始采用更为高效和准确的方法。 例如,最大熵模型和支持向量机等机器学习算法开始应用于文本分类、信息检索和命名实体识别等任务。2010年代后期,随着深度学习技术的快速发展,自然语言处理进入了一个新的时代。深度神经网络,特别是循环神经网络(RNN)和卷积神经网络(CNN),开始应用于各种NLP任务。Transformer、BERT、GPT-3模型的出现进一步推动了自然语言处理的进步和发展。
自然语言处理(NLP)的发展历史可以追溯到20世纪50年代,从最初的基于规则、统计方法,到现代的深度学习、机器学习技术, 自然语言处理的早期尝试开始于1950年代。研究者开始使用规则基础的方法来解决自然语言处理问题,例如通过编写语法规则来进行句法分析。1970年代至1990年代,随着统计学的引入,自然语言处理开始转向基于数据的方法,研究者开始使用统计模型来处理语言问题 ,进入21世纪,随着机器学习的崛起,自然语言处理开始采用更为高效和准确的方法。 例如,最大熵模型和支持向量机等机器学习算法开始应用于文本分类、信息检索和命名实体识别等任务。2010年代后期,随着深度学习技术的快速发展,自然语言处理进入了一个新的时代。深度神经网络,特别是循环神经网络(RNN)和卷积神经网络(CNN),开始应用于各种NLP任务。Transformer、BERT、GPT-3模型的出现进一步推动了自然语言处理的进步和发展。
常用软件

Gensim

Transformers

TextBlob

Stanford CoreNLP

NLTK
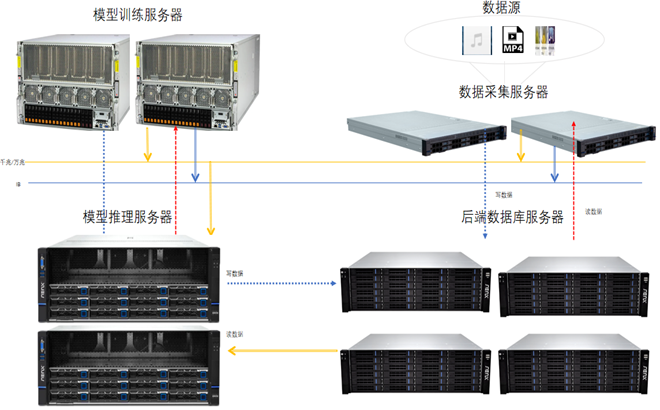
数据处理流程与硬件选择




解决方案
除了硬件配置以外还可以采用集群方式部署大模型,多节点、多卡之间互联可以提高网络带宽,实现大模型在高算力下的数据互通效率,提高大模型的训练效果;模型训练包含多种计算模式,例如:数据并行、流水线并行、张量并行,这些并行计算方式是提升训练效率的关键,计算模式需要多个计算设备进行集合通信,模型并行时机内与机外的集合通信操作会产生大量的通信数据量。产生的集合通信数据量将达到百GB级别,且复杂的集合通信模式将在同一时刻产生多对一或一对多的通信,因此机间GPU的高速互联对于网络的单端口、双端口带宽、节点间的可用链路数量及网络总带宽都有严格的要求,选择基于RoCE和RdMA协议的以太网和Infiniband网络可以解决机内机外数据的互联、相应效率瓶颈问题,另一方面也可以降低多机多卡间数据同步的通信耗时,提升GPU有效计算时间占比。