行业背景
LLM(Large Language Model)技术是一种基于深度学习的自然语言处理技术,旨在训练能够处理和生成自然语言文本的大型模型,核心思想是使用深度神经网络,通过大规模的文本数据预训练模型,并利用这些预训练模型进行下游任务的微调或直接应用。
LLM 技术的主要特点是可以从大规模文本数据中学习到丰富的语言知识和语言模式,使得模型能够对自然语言的语义、语法等进行理解和生成,具备更强的语言处理能力
LLM已经在许多领域产生了深渊的影响。在自然语言处理领域,它可以帮助计算机更好地理解和生成文本,包括写文章、回答问题、翻译语言。在信息检索领域,它可以改进搜索引擎,让我们更轻松地找到所需的信息
LLM 技术的主要特点是可以从大规模文本数据中学习到丰富的语言知识和语言模式,使得模型能够对自然语言的语义、语法等进行理解和生成,具备更强的语言处理能力
LLM已经在许多领域产生了深渊的影响。在自然语言处理领域,它可以帮助计算机更好地理解和生成文本,包括写文章、回答问题、翻译语言。在信息检索领域,它可以改进搜索引擎,让我们更轻松地找到所需的信息
行业技术





LLM主要特点

巨大的规模
LLM通常具有巨大的参数规模,可以达到数十亿甚至数千亿个参数。这使得它们能够捕捉更多的语言知识和复杂的语法结构。
预训练和微调
LLM采用了预训练和微调的学习方法。它们首先在大规模文本数据上进行预训练(无标签数据),学会了通用的语言表示和知识,然后通过微调(有标签数据)适应特定任务,从而在各种NLP任务中表现出色。

上下文感知
LLM在处理文本时具有强大的上下文感知能力,能力理解和生成依赖于前文的文本内容。这使得它们在对话、文章生成和情境理解方面表现出色。

多模态支持
一些LLM已经扩展到支持多模态数据,包括文本、图像和语音。这意味着它们可以理解和生成不同媒体类型的内容,实现更多样化的应用。
常用模型软件

LLaMA(7B到70B)

ChatGLM/ChatGLM 2

Qwen-7B-Chat

Qwen-14B-Chat
算力和存储需求
对于计算精度,我们需要计算整体的计算量,基于Transformer架构,整体的计算量由前向传播和后向传递组成,因此整体的通用计算量为总步数*(前向传播+后向传递)=6*模型参数量*总tokens数据

存储
使用NVMe SSD可以显著提高数据读写速度,保障数据的快速存取。
网络接口:尽量选择IB网络作为数据传输网络
网络接口:尽量选择IB网络作为数据传输网络
内存
足够的内存可以提升多任务处理能力。一般建议至少512G内存
GPU协处理器
推荐使用支持CUDA的NVIDIA GPU,如Tesla系列

对于推理应用,由于推理主要针对模型的优化及并发应用,因此我们更加推荐符合要求的硬件产品,具体如下:
GPU协处理器
推荐使用支持CUDA的NVIDIA GPU,如Tesla系列,可以考虑T4/A10等产品
内存
足够的内存可以提升多任务处理能力。一般建议至少128GB的内存,对于高性能推理服务器,可以搭配256GB或更高的DDR5内存
存储
使用NVMe SSD可以显著提高数据读写速度,保障数据的快速存取。

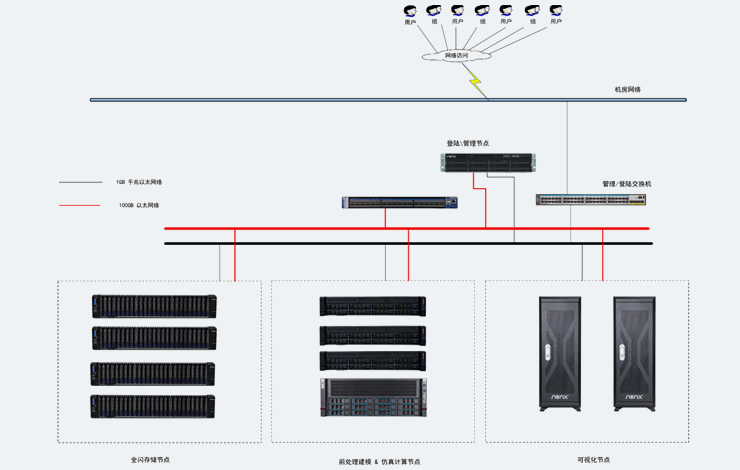
针对于LLM中涉及到的存储要求,由于Transformer架构的原因,训练数据需要循环读写存储,因此需要一套高读写,低延迟的及高稳定性的存储,传统的集中存储不推荐在本架构中使用,我们更加推荐分布式并行系统
存储
使用NVMe SSD可以显著提高数据读写速度,保障数据的快速存取,整体读写要求:≥2GB/S

解决方案
LLM(Large Language Model)技术是一种基于深度学习的自然语言处理技术,通过大规模的文本数据预训练模型使得模型能够对自然语言的语义、语法等进行理解和生成,具备更强的语言处理能力
LLM已经在许多领域产生了深渊的影响。在自然语言处理领域,它可以帮助计算机更好地理解和生成文本,包括写文章、回答问题、翻译语言;在信息检索领域,它可以改进搜索引擎,让我们更轻松地找到所需的信息
LLM已经在许多领域产生了深渊的影响。在自然语言处理领域,它可以帮助计算机更好地理解和生成文本,包括写文章、回答问题、翻译语言;在信息检索领域,它可以改进搜索引擎,让我们更轻松地找到所需的信息